
<aside> 💡 Overfitting 機器學習中,過度學習是一個很常見的問題,過度學習指的是過度適應訓練數據,但不能順利應用到訓練資料以外的其他數據。
</aside>
發生過度學習的原因,主要有兩個:
以下刻意滿足上述條件引起過度學習:從數據樣本中選取少量(60,000 →300)的訓練數據,為了提高網絡的複雜度,使用7層網路(每層100個神經元,使用ReLU活化函數)
可以看到上面過了100個epoch後,訓練數據的精度達到了100%,而測試數據精度則不行,這是一個典型的過擬合
<aside> 💡 權重衰減是一直以來經常用於抑制過度學習的方法,該方法通過在學習過程中對大的權重進行懲罰來抑制過度學習
為損失函數加上權重的平方範數,這樣可以抑制權重變大,如果將權重記為W, 權重的平方和正規化(L2 norm)的權重衰減就是$\frac{1}{2}λW^2$,然後L2 norm與損失函數相加,因此,在求權重梯度的計算中,要為之前的誤差反向傳播法的結果加上正則化項的導入λW。 ($\frac{1}{2}λW^2$的微分值/導數 是λW)
λ: 控制正規化強度的超參數,設置得越大,對大的權重施加的懲罰就越重
</aside>
<aside> 💡 $L1 \ norm$ 絕對值和正規化(Manhattan Distance): 對應各元素的絕對值和
假設權重 $W = (w_1, w_2, ..., w_n )$, $|w_1|, |w_2|, ..., |w_n| ⇒ L1 \ norm$
</aside>
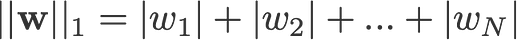
1-norm (also known as L1 norm)